My Work at Oxford: Applying DITTO to Nocturne
This is my final report from my time at Oxford during Michaelmas 2023. Specifically, I wanted to put all of my weekly updates into a summary that reflects the entire process and motivation of the project. Most of the content may be derived from the weekly updates, but I thought it would still be helpful to consolidate all of them into one place.
Introduction
At a high-level, my work at Oxford concerned applying Dream Imitation (DITTO) -- an off-line, imitation learning algorithm within world models -- to the Nocturne RL environment -- a 2D driving simulator for investigating multi-agent coordination under partial observability. In particular, I worked on building a world model for Nocturne as well as training both beahvior cloning (BC) and actor-critic (AC) agents on this trained world model. In terms of future work, the most low-hanging fruit is creating a more robust world model for Nocturne to run better experiments.
Overview of Nocturne
The first part of the project involved setting up Nocturne, which is an RL environment for driving. In particular, the goal of the project is to support research in self-driving without the complications of computer vision while still modeling partial observability. More information can be found on their repository page.
Training a Behavior Cloning Agent on Nocturne
The first step of the project was training a standard Behavior Cloning agent on Nocturne and visualizing a rollout of its policy. Behavior Cloning is a part of a set of techniques known as Imitation Learning, which is the study of algorithms that improve performance by observing demonstrations from a teacher. Specifically, we aim to learn a stochastic policy that maps states to actions and learns parameters . This policy will learn from collected human driver demonstrations and output expert actions with high likelihood. More information on the specifics of the Behavior Cloning for Nocturne can be found using Daphne's great tutorial.
To run the agent, I followed Daphne's tutorial to train a policy and saved the weights. I then wrote a function that takes the same BC agent and rolls it out to a specific scenario within the Nocturne environment. Overall, since the agent only learns on such few demonstrations, the agent is not able to perform relatively well and gets derailed quite quickly.
Overview of World Models
The second step of the project was training a world model for Nocturne. At a high-level, world models (WMs) build generative neural networks of RL enviroinments. WMs are trained in an unsupervised manner, and learn a compressed spatial and temporal representation of the environment. We can then use this model to train an agent, sometimes even training agent in its own dream environment and transferring the policy to the real task. In DITTO, the authors adapt the recurrent state space model (RSSM) introduced in the DreamerV2 paper.
Gathering Data for the World Model
The DITTO codebase trains a WM based on episodes of a strong Proximal Policy Optimization agent playing Breakout. Each of these files were .npz files and contained information containing images of the state, actions taken by the player, the total rewards gained, whether the game was reset or not, and if the state was a terminal state.
As part of the Nocturne codebase, you can download a dataset from Waymo that contains traffic scenes. Each traffic scene consists of a name, road objects and vehicles in the scene, roads, and the states of traffic lights. We can then wrap each of these traffic scenes as a Nocturne simulation, which consists of discretezed traffic scenarios that are snapshots of a traffic situation at a paricular timepoint. Each simulation lasts for 9 seconds, and they are discretized into step sizes of 0.1 seconds, meaning there are 90 total timesteps.
Creating the dataset
For each simulation, I then followed the below procedure to generate episodes:
- First, I loaded in the traffic simulation, and set all vehicles to be expertly controlled, which corresponds to how the cars actually moved in the real-life dataset.
- For all of the vehicles that moved in the traffic scene, I found a vehicle that was moving (i.e., took an action) at each timestep across the entire episode. I labeled this vehicle the ego vehicle.
- After finding an ego vehicle, I then retrieved its action at each timestep (Nocturne has functionality that allows you to retrieve the expert action at each timestep), and also obtained an image of the scene from the perspective of the ego vehicle (Figure 1).
- Finally, I saved this data into a
.npzfile to use for training.

Figure 1: Sample cone image from a Nocturne vehicle agent.
A Note on the Nocturne Action Space
The action set for a vehicle consists of three components: acceleration, steering, and the head angle. Actions are discretized based on an upper and lower bound.
For the data I was looking through (the mini dataset), all of the head angles were set to 0. Thus, I only had to decide on the discretization for the acceleration and steering. In both instances, I took the following steps, I collected all of the corresponding metrics across all vehicles in all traffic scenes at each time step. Then, I generated a histogram and visualized where appropriate upper and lower bounds would be.
After the above, I found that the acceleration could be bounded by [-6, 6], with 13 discrete buckets, and that the steering could be bounded by [-1, 1] with 21 discrete buckets.
Finally, when reporting the final action, I effectively mapped the two actions into a single action. I did this by finding an index for both the acceleration and steering index based on the bounds and discrete buckets. Since this effectively like indexing into a 2D-array, I then imagined "flattening" the 2D-array and finding the corresponding index in the now 1D-array.
Training the World Model
In general, just to align alongside of the existing DITTO code, not much had to be changed to train a world model for Nocturne. In particular, perhaps the biggest change was defining the correct dimensionality of the action space to ensure that the function fix_actions would appropriately encode each action as a one-hot vector.
After training for a bit, one issue that I found was that the images were being resized into 64 by 64 pixel images. While these sizes worked for Breakout, given the vast amount of details provided in a sample Nocturne scenario, I decided to try and increase the size of the image that the model would reproduce. Specifically, I tried to output images of 128 by 128 pixel dimensions.
This took a bit of time and a lot of changing around, but I was able to get it done. The steps I took were the following:
- Adjusting the
cnn_depthwithinconfig.pyof the Recurrent State Space Model (RSSM) to align with the eventual output of the encoder in the WM architecture - Adding an extra pair of an Activation and Transpose 2D Convolutional Layer at the end of the decoder to ensure that the output was 128 by 128
Ultimately, I found that the code was able to work, the loss was going down, and that the images were being reconstructed (Figure 2)!

Figure 2: Example reconstruction of Nocturne image from World Model.
Overview of DITTO
DITTO's core contribution is the optimization of a novel distance measure defined in the latent space of a learned world model. This measure is created by rolling out a learned policy in the latent space of a learned world model, and then computing the divergence from expert trajectories over multiple time steps. This reward is then minimized through on-policy reinforcement learning. Amongst other things, by training within the WM and learning a policy under its own induced state distribution, one of the primary issues this approach addresses is covariate shift in imitation learning. This is specifically when a policy fails at test time, meaning that the distribution of states it encounters is different from training, thus leading to further downstream compounding errors.
Training a BC Agent on the World Model
The final step I took was training agents within the world model of Nocturne. I started with training a BC agent that takes the latents generated by the WM, uses the policy to predict a distribution of potential actions, and computed the cross-entropy loss between the true actions taken by the expert and the actions predicted by the agent.
Within the DITTO codebase, training a BC agent on the latents is a part of the normal training loop of the actor-critic policy. An experimental training run showed that the loss was indeed going down (Figure 3).
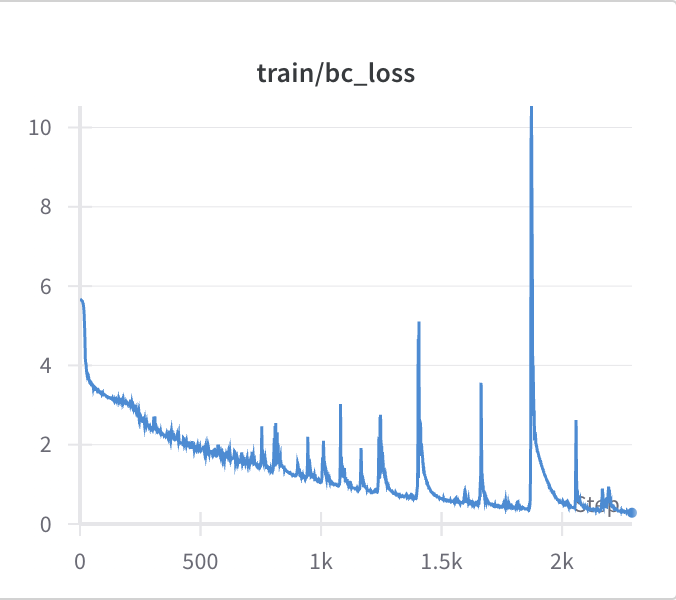
Figure 3: Loss from BC agent trained on latents of Nocturne WM.
To visualize the rollout of a BC agent in the latent space, I wrote a function that loops to grab the current latent state, uses the policy to generate a set of actions, and then uses those actions and current state to dream, or take a step in the WM. Further, the state returned after taking a step in the WM can be utilized to recreate an actual observation from the WM: all I had to do was index into the first dimension of the state (since the function still returned batched observation) so I could retrieve the properly sized latent that could be passed into the decoder. From there, I was able to write a function for the decoder that was able to recover an image just from the latents (no existing function with this sole job), and I was able to generate what the world model would look like after taking an action in the latent space:

Figure 4: A reconstruction of the visualization of the Nocturne environment from a step in the latent space of the world model.
Training an Actor-Critic Agent on the World Model
Finally, the last agent I trained was the actor-critic agent. As outlined in the DITTO paper, the authors used an agent composed of a stochastic actor which samples actions from a learned policy with parameter vector , and a deterministic critic which predicts the expected sum of future rewards the actor will achieve from the current state with parameter vector .
Overall, the training loop works without error, with the main issue being fixing the validation part of training. While I was able to fix the issues regarding the validation function at least once, the issues still remain open and require a bit of debugging, with some notes from listed in the weekly reports. However, perhaps the most important contribution is writing a new function for validation for Nocturne, which involves:
- Generating an image from a timestep and turning it into a latent state using the world model.
- Feeding the latent state observation into the model to produce an action.
- Turning the singular integer action back into a pair of acceleration and steering parameters.
- Repeating this loop for a certain amount of games and recording validation statistics.
Future Work
Overall, there is much future work to tighten all of the loose ends, given the bulk of this experimental work The most relevant fix is improving upon the existing world model, which includes potential steps such as:
- Training for more timesteps
- Even higher input image size, such as 256 by 256
- More depth for the CNN itself
Outside of that, making sure the validation code for works for the actor-critic policy is also crucial.